Chapter 3 Data transformation

3.1 Glassdoor
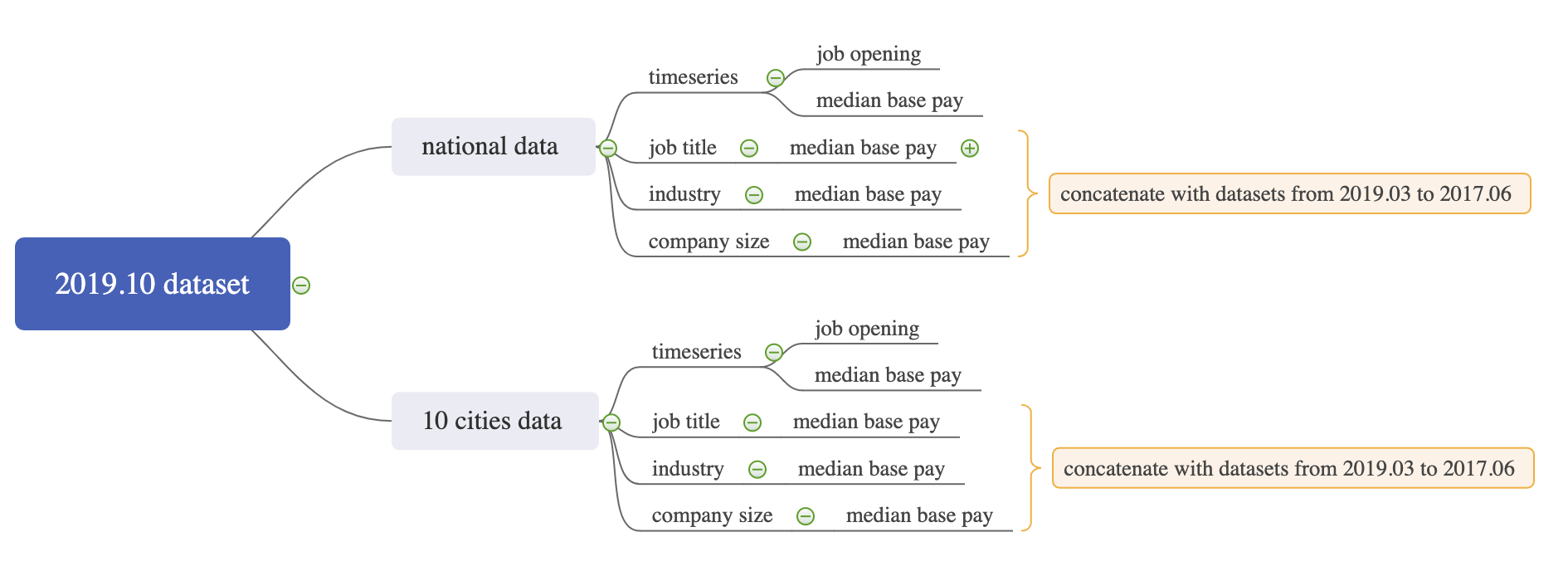
The raw dataset is monthly. In order to explore the temporal changes of median base pay, we first concatenated the 22 datasets into a single data frame.
Since national data and city level data are on different levels, we separated the dataset into two main categories: national level and city levels.
The next step is to construct the datasets containing only the variables we are interested in, which are for futher analysis. Here are a few examples:
- In order to focus on the relationship between job title and median base pay, we subsetted the corresponding dataset:
## # A tibble: 6 x 8
## X1 Metro Dimension.Type Month Dimension Measure Value YoY
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 127 Atlan… Job Title 2019-… Accountant Median B… $58,6… 2.20%
## 2 128 Atlan… Job Title 2019-… Administrative… Median B… $43,2… 1.90%
## 3 129 Atlan… Job Title 2019-… Attorney Median B… $105,… -2.2…
## 4 130 Atlan… Job Title 2019-… Bank Teller Median B… $33,2… 6.70%
## 5 131 Atlan… Job Title 2019-… Barista Median B… $23,6… 3.90%
## 6 132 Atlan… Job Title 2019-… Bartender Median B… $36,8… 14.1…- In order to find out the secular and cyclical trend of median base pay, we subsetted the corresponding dataset:
## # A tibble: 6 x 8
## X1 Metro Dimension.Type Month Dimension Measure Value YoY
## <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <lgl>
## 1 1440 U.S. Timeseries 2019-… Metro Median B… Median Ba… 54327. NA
## 2 1441 U.S. Timeseries 2019-… Metro Median B… Median Ba… 54175. NA
## 3 1442 U.S. Timeseries 2019-… Metro Median B… Median Ba… 54023. NA
## 4 1443 U.S. Timeseries 2019-… Metro Median B… Median Ba… 53860. NA
## 5 1444 U.S. Timeseries 2019-… Metro Median B… Median Ba… 53647 NA
## 6 1445 U.S. Timeseries 2019-… Metro Median B… Median Ba… 53525 NAWe did the subsetting for all possible dimensions and got 10 separate datasets in total: na_industry, na_jobtitle, na_size, na_ts_opening, na_ts_pay, city_industry, city_jobtitle, city_size and city_ts. As for the filenames, na stands for national; ts stands for timeseries; size stands for company size; opening stands for job opening; pay stands for median base pay.
Here is a graph indicates the structure of the cleaning process
3.2 Indeed
We used Indeed dataset in two parts of the analysis and conducted the data cleaning process differently based on different needs:
- To find out the regional distribution pattern of the four data related jobs we are interested in: data analyst, data scientist, business analyst and financial analyst, we scraped all the search results from indeed using the four job titles, then grouped the jobs by state and finally counted their numbers.
## # A tibble: 6 x 7
## X1 state jo_ba jo_da jo_ds jo_fa jo_total
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 AL 6 2 11 16 35
## 2 2 AR 6 12 4 6 28
## 3 3 AZ 131 20 14 19 184
## 4 4 CA 223 177 298 242 940
## 5 5 CO 48 38 64 41 191
## 6 6 CT 23 107 13 13 156- We need to plot wordclouds to help us analyze. In python, we vectorized the details by 1-gram and 2-gram, removing common English stopwords and some less informative words. Then we combined 1-gram and 2-gram into one list. The final result is in the form of word vs. frequency.
3.3 City data
The goal of the data cleaning is to map city statistics to 10 cities.
The median income column should be numeric, but they are characters with dollar signs and commas. Thus we removed the dollar signs and commas, and then convert them to numeric forms.
Firstly we used two for loops to map the city statistics into cities. However, the city names in each dataset are different, which led to some mismatches. To fix it, we assigned the values manually.
There is no value of all_median_income in Atlanta in 2018. In order to draw the parallel coordinates plot, we found this value from somewhere else.
To find the patterns in different cities, I standardized the data before drawing the parallel coordinates plot.